一致性哈希算法在 1997 年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系.一致性哈希解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题
优点
- 可扩展性.一致性哈希算法保证了增加或减少服务器时,数据存储的改变最少,相比传统哈希算法大大节省了数据移动的开销 。
- 更好地适应数据的快速增长.采用一致性哈希算法分布数据,当数据不断增长时,部分虚拟节点中可能包含很多数据、造成数据在虚拟节点上分布不均衡,此时可以将包含数据多的虚拟节点分裂,这种分裂仅仅是将原有的虚拟节点一分为二、不需要对全部的数据进行重新哈希和划分。虚拟节点分裂后,如果物理服务器的负载仍然不均衡,只需在服务器之间调整部分虚拟节点的存储分布。这样可以随数据的增长而动态的扩展物理服务器的数量,且代价远比传统哈希算法重新分布所有数据要小很多。
与哈希算法的关系
一致性哈希算法是在哈希算法基础上提出的,在动态变化的分布式环境中,哈希算法应该满足的几个条件:平衡性、单调性和分散性
- 平衡性:是指 hash 的结果应该平均分配到各个节点,这样从算法上解决了负载均衡问题
- 单调性:是指在新增或者删减节点时,不影响系统正常运行
- 分散性:是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据
原理
一致性哈希算法通过一个叫作一致性哈希环的数据结构实现。这个环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 [0, 2^32-1]
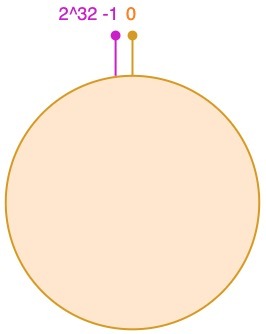
放置对象到哈希环
现有存储对象o1、o2、o3 和 o4,服务器对象cs1、cs2 和 cs3.将存储对象和服务器对象hash后放到哈希环上.
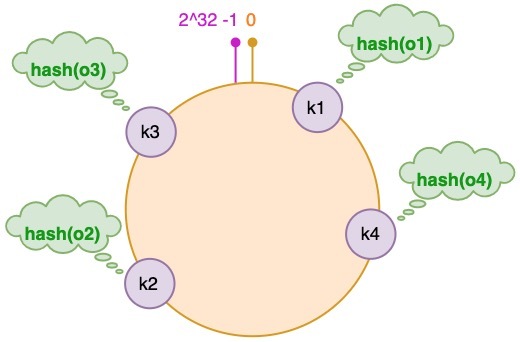
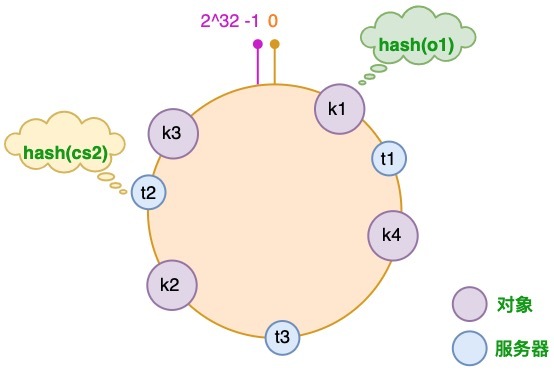
为对象选择服务器
将对象和服务器都放置到同一个哈希环后,在哈希环上顺时针查找距离这个对象的 hash 值最近的机器,即是这个对象所属的机器。 以 o2 对象为例,顺序针找到最近的机器是 cs2,故服务器 cs2 会缓存 o2 对象。而服务器 cs1 则缓存 o1,o3 对象,服务器 cs3 则缓存 o4 对象
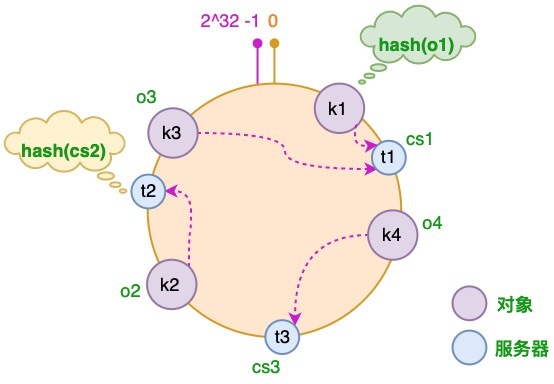
服务器增加的情况
假设由于业务需要,我们需要增加一台服务器 cs4,经过同样的 hash 运算,该服务器最终落于 t1 和 t2 服务器之间
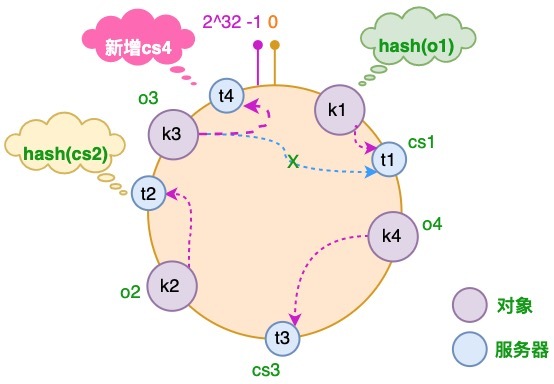
对于上述的情况,只有 t1 和 t2 服务器之间的对象需要重新分配.在以上示例中只有 o3 对象需要重新分配,即它被重新到 cs4 服务器。在前面我们已经分析过,如果使用简单的取模方法,当新添加服务器时可能会导致大部分缓存失效,而使用一致性哈希算法后,这种情况得到了较大的改善,因为只有少部分对象需要重新分配
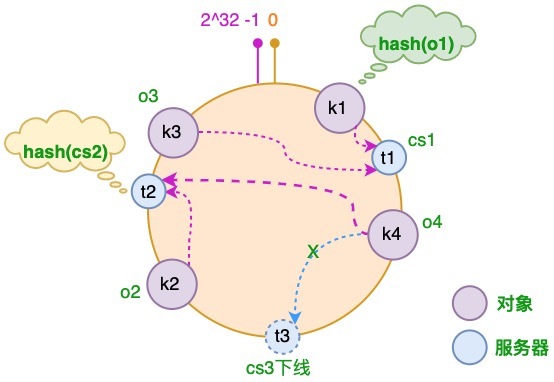
服务器减少的情况
假设 cs3 服务器出现故障导致服务下线,这时原本存储于 cs3 服务器的对象 o4,需要被重新分配至 cs2 服务器,其它对象仍存储在原有的机器上
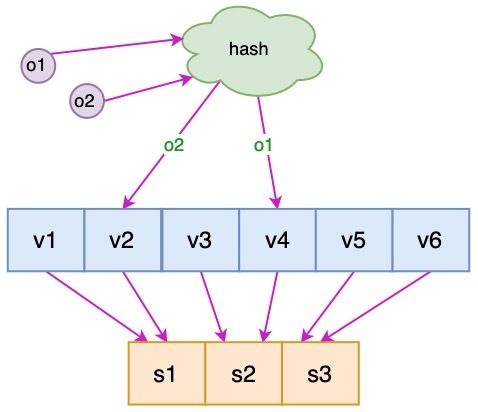
虚拟节点
新增的服务器 cs4 只分担了 cs1 服务器的负载,服务器 cs2 和 cs3 并没有因为 cs4 服务器的加入而减少负载压力。如果 cs4 服务器的性能与原有服务器的性能一致甚至可能更高,那么这种结果并不是我们所期望的
针对这个问题,我们可以通过引入虚拟节点来解决负载不均衡的问题。即将每台物理服务器虚拟为一组虚拟服务器,将虚拟服务器放置到哈希环上,如果要确定对象的服务器,需先确定对象的虚拟服务器,再由虚拟服务器确定物理服务器
文章链接 https://fangzongzhou.github.io/2021/01/27/计算机/算法/一致性哈希算法/